Python Web Scraping: Проверьте, содержит ли страница заголовок или нет
Python Web Scraping: Упражнение 11 с решением
Напишите программу на Python, чтобы проверить, содержит ли страница заголовок или нет.
Пример решения : -
Код Python:
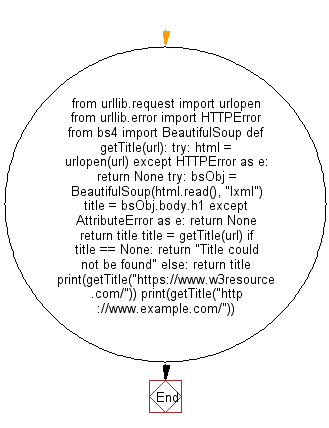
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(), "lxml")
title = bsObj.body.h1
except AttributeError as e:
return None
return title
title = getTitle(url)
if title == None:
return "Title could not be found"
else:
return title
print(getTitle("/"))
print(getTitle("http://www.example.com/"))
Выход:
Никто <h1> Пример домена </ h1>
Блок - схема:
Редактор кода Python:
Есть другой способ решить это решение? Внесите свой код (и комментарии) через Disqus.
Предыдущий: Напишите программу на Python, которая извлекает произвольную страницу «Python» из Википедии и создает список ссылок на этой странице.
Далее: Напишите программу на Python, чтобы перечислить все названия языков и количество связанных статей в порядке их появления на wikipedia.org.
Каков уровень сложности этого упражнения?
Новый контент: Composer: менеджер зависимостей для PHP , R программирования
disqus2code