
NoSQL
Вступление
В вычислительной системе (веб-приложения и бизнес-приложения) из Интернета ежедневно поступают огромные данные. Большая часть этих данных обрабатывается системами управления реляционными базами данных (RDBMS). Идея реляционной модели появилась в статье EFCodd 1970 года «Реляционная модель данных для больших общих банков данных», которая значительно упростила моделирование данных и прикладное программирование. Помимо предполагаемых преимуществ, реляционная модель хорошо подходит для программирования клиент-сервер, и сегодня она является преобладающей технологией для хранения структурированных данных в веб-приложениях и бизнес-приложениях.
База данных классических отношений соответствует правилам ACID
Транзакция базы данных должна быть атомарной, последовательной, изолированной и долговечной. Ниже мы обсудили эти четыре пункта.
Атомная: транзакция - это логическая единица работы, которая должна быть либо завершена со всеми изменениями данных, либо ни одна из них не выполнена.
Согласованно: в конце транзакции все данные должны оставаться в согласованном состоянии.
Изолированный: модификации данных, выполняемые транзакцией, должны быть независимыми от другой транзакции. Если это не произойдет, результат транзакции может быть ошибочным.
Долговечный: по завершении транзакции эффекты изменений, выполненных транзакцией, должны быть постоянными в системе.
Часто эти четыре свойства транзакции обозначаются как ACID .
Распределенные системы
Распределенная система состоит из нескольких компьютеров и программных компонентов, которые взаимодействуют через компьютерную сеть (локальную сеть или глобальную сеть). Распределенная система может состоять из любого числа возможных конфигураций, таких как мэйнфреймы, рабочие станции, персональные компьютеры и т. Д. Компьютеры взаимодействуют друг с другом и совместно используют ресурсы системы для достижения общей цели.
Преимущества распределенных вычислений
Надежность (отказоустойчивость):
Важным преимуществом распределенной вычислительной системы является надежность. Если на некоторых компьютерах системы происходит сбой, остальные компьютеры остаются без изменений и работа не останавливается.
Масштабируемость:
В распределенных вычислениях система может быть легко расширена путем добавления большего количества машин по мере необходимости.
Совместное использование ресурсов:
Совместно используемые данные имеют важное значение для многих приложений, таких как банковское дело, система бронирования. Поскольку данные или ресурсы совместно используются в распределенной системе, другие ресурсы также могут совместно использоваться (например, дорогие принтеры).
Гибкость:
Поскольку система очень гибкая, ее очень легко устанавливать, внедрять и отлаживать новые сервисы.
Скорость:
Распределенная вычислительная система может иметь большую вычислительную мощность, а ее скорость отличает ее от других систем.
Открытая система :
Поскольку это открытая система, каждый сервис одинаково доступен для каждого клиента, то есть локального или удаленного.
Спектакль :
Совокупность процессоров в системе может обеспечить более высокую производительность (и лучшее соотношение цена / производительность), чем централизованный компьютер.
Недостатки распределенных вычислений
Поиск проблемы :
Устранение неисправностей и диагностика проблем.
Программного обеспечения :
Меньшая поддержка программного обеспечения является основным недостатком распределенной вычислительной системы.
Сеть:
Сетевая инфраструктура может создать несколько проблем, таких как проблема передачи, перегрузка, потеря сообщений.
Безопасность :
Простой доступ в распределенной вычислительной системе увеличивает риск безопасности, а совместное использование данных порождает проблему безопасности данных.
Масштабируемость
В электронике (включая аппаратное обеспечение, связь и программное обеспечение) масштабируемость - это способность системы расширяться в соответствии с потребностями вашего бизнеса. Например, масштабирование веб-приложения - это все, что позволяет большему количеству людей использовать ваше приложение. Вы масштабируете систему, обновляя существующее оборудование, не меняя большую часть приложения, или добавляя дополнительное оборудование.
Существует два способа масштабирования по горизонтали и по вертикали:
Вертикальное масштабирование
Вертикальное масштабирование (или увеличение) означает добавление ресурсов в одну и ту же логическую единицу для увеличения емкости. Например, для добавления процессоров к существующему серверу, увеличения памяти в системе или расширения хранилища путем добавления жесткого диска.
Горизонтальное масштабирование
Горизонтальное масштабирование (или масштабирование) означает добавление большего количества узлов в систему, например, добавление нового компьютера в распределенное программное приложение. В системе NoSQL хранилище данных может быть намного быстрее, поскольку оно использует «масштабирование», что означает добавление большего количества узлов в систему и распределение нагрузки по этим узлам.
Что такое NoSQL?
NoSQL - это нереляционные системы управления базами данных, отличающиеся от традиционных систем управления реляционными базами данных некоторыми существенными способами. Он предназначен для распределенных хранилищ данных, где требуется очень большой объем данных (например, Google или Facebook, который ежедневно собирает терабиты данных для своих пользователей). Хранение данных такого типа может не требовать фиксированной схемы, избегать операций объединения и обычно масштабируется горизонтально.
Почему NoSQL?
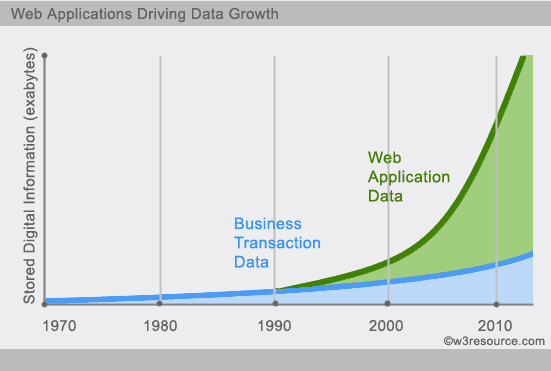
В настоящее время доступ к данным и сбор данных через третьих лиц, таких как Facebook, Google+ и другие, становится все проще. Личная информация о пользователях, социальные графики, данные о географическом местоположении, пользовательский контент и данные машинного журнала - это всего лишь несколько примеров, когда данные росли в геометрической прогрессии. Для правильного использования вышеуказанного сервиса требуется обработка огромного количества данных. Какие базы данных SQL никогда не проектировались. Эволюция баз данных NoSql заключается в правильной обработке этих огромных данных.
Пример :
Граф социальной сети:
Each record: UserID1, UserID2
Separate records: UserID, first_name,last_name, age, gender,...
Task: Find all friends of friends of friends of ... friends of a given user.
Страницы Википедии:
Large collection of documents
Combination of structured and unstructured data
Task: Retrieve all pages regarding athletics of Summer Olympic before 1950.
СУБД против NoSQL
RDBMS
- структурированные и организованные данные
- язык структурированных запросов (SQL)
- Данные и их взаимосвязи хранятся в отдельных таблицах.
- Язык манипулирования данными, язык определения данных
- Плотная последовательность
NoSQL
- обозначает не только SQL
- Нет декларативного языка запросов
- Нет предопределенной схемы
- хранилище пар ключ-значение, хранилище столбцов, хранилище документов, базы данных графиков
- Возможная согласованность, а не свойство ACID
- неструктурированные и непредсказуемые данные
- CAP Теорема
- Приоритеты высокая производительность, высокая доступность и масштабируемость
- БАЗОВАЯ сделка
Краткая история NoSQL
Термин NoSQL был придуман Карло Строцци в 1998 году. Он использовал этот термин для обозначения своей Open Source, Light Weight, DataBase, у которой не было интерфейса SQL.
В начале 2009 года, когда last.fm захотел организовать мероприятие по распределенным базам данных с открытым исходным кодом, Эрик Эванс, сотрудник Rackspace, повторно использовал этот термин для обозначения баз данных, которые не являются реляционными, распределенными и не соответствуют атомарности, согласованности Изоляция, долговечность - четыре очевидные особенности традиционных систем реляционных баз данных.
В том же году на конференции «No: sql (east)», проходившей в Атланте, США, NoSQL широко обсуждалась и обсуждалась.
А затем обсуждение и практика NoSQL получили импульс, и NoSQL увидел беспрецедентный рост.
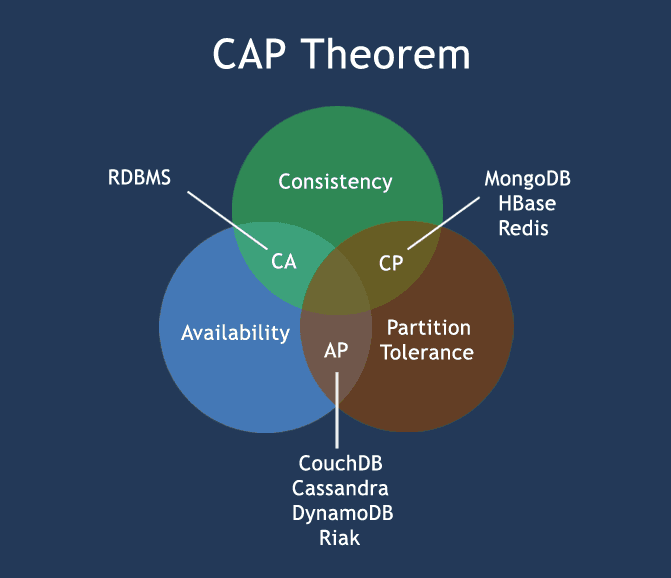
CAP Теорема (Теорема Брюера)
Вы должны понимать теорему CAP, когда говорите о базах данных NoSQL или фактически при разработке любой распределенной системы. Теорема CAP гласит, что существуют три основных требования, которые существуют в особом отношении при разработке приложений для распределенной архитектуры.
Согласованность - это означает, что данные в базе данных остаются согласованными после выполнения операции. Например, после операции обновления все клиенты видят одни и те же данные.
Доступность - это означает, что система всегда включена (сервисная гарантия доступности), без простоев.
Допуск разделения - это означает, что система продолжает функционировать, даже если связь между серверами ненадежна, то есть серверы могут быть разделены на несколько групп, которые не могут общаться друг с другом.
Теоретически невозможно выполнить все 3 требования. CAP обеспечивает основные требования для распределенной системы, чтобы выполнить 2 из 3 требований. Поэтому все текущие базы данных NoSQL следуют различным комбинациям C, A, P из теоремы CAP. Вот краткое описание трех комбинаций CA, CP, AP:
CA - один кластер сайта, поэтому все узлы всегда находятся в контакте. Когда происходит разделение, система блокируется.
CP - некоторые данные могут быть недоступны, но остальные все еще последовательны / точны.
AP - Система по-прежнему доступна при разбиении, но некоторые возвращенные данные могут быть неточными.
NoSQL плюсы / минусы
Преимущества :
- Высокая масштабируемость
- Распределенных вычислений
- Более низкая стоимость
- Гибкость схемы, полуструктура данных
- Нет сложных отношений
Недостатки
- Нет стандартизации
- Ограниченные возможности запросов (пока)
- Последовательное согласование не является интуитивно понятным для программирования
База
Теорема CAP утверждает, что распределенная компьютерная система не может гарантировать все следующие три свойства одновременно:
- консистенция
- Доступность
- Допуск раздела
БАЗОВАЯ система отказывается от согласованности.
- B asically показывает , что модели шириной система не гарантирует наличие, в терминах теоремы CAP.
- S oft state указывает, что состояние системы может меняться со временем, даже без ввода. Это из-за возможной модели согласованности.
- E ventual консистенция указывает на то, что система будет соответствовать в течение долгого времени, учитывая , что система не получает входной сигнал в течение этого времени.
КИСЛОТА против БАЗЫ
| ACID | БАЗА |
|---|---|
| атомное | B asically A доступный |
| C onsistency | S oft State |
| Я солитация | E вентуальная последовательность |
| D urable |
BigTable, Кассандра, SimpleDB
Категории NoSQL
Существует четыре основных типа (наиболее распространенные категории) баз данных NoSQL. Каждая из этих категорий имеет свои специфические атрибуты и ограничения. Нет единого решения, которое лучше, чем все остальные, однако есть некоторые базы данных, которые лучше решают конкретные проблемы. Чтобы прояснить базы данных NoSQL, давайте обсудим наиболее распространенные категории:
- Ключ-значение магазинов
- Колонна-ориентированной
- график
- Ориентированный на документ
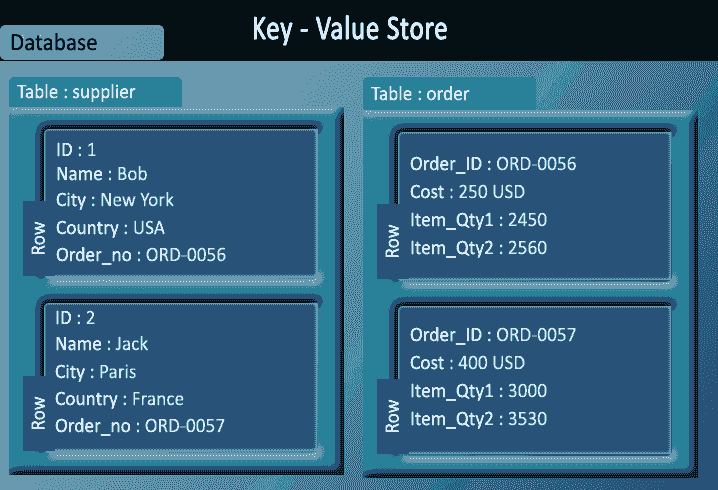
Ключ-значение магазинов
- Хранилища ключей и значений являются основными типами баз данных NoSQL.
- Предназначен для обработки огромных объемов данных.
- По материалам динамо Амазонки.
- Хранилища значений ключей позволяют разработчику хранить данные без схемы.
- В хранилище значений ключей база данных хранит данные в виде хеш-таблицы, где каждый ключ уникален, и значением может быть строка, JSON, BLOB (большой двоичный объект) и т. Д.
- Ключом могут быть строки, хэши, списки, наборы, отсортированные наборы и значения, хранящиеся в этих ключах.
- Например, пара ключ-значение может состоять из ключа типа «Имя», который связан со значением типа «Робин».
- Хранилища Key-Value можно использовать в качестве коллекций, словарей, ассоциативных массивов и т. Д.
- Хранилища Key-Value следуют аспектам теоремы CAP «Доступность» и «Разделение».
- Магазины Key-Values хорошо подойдут для содержимого корзины покупок или отдельных значений, таких как цветовые схемы, URI целевой страницы или номер учетной записи по умолчанию.
Пример базы данных Key-value: Redis, Dynamo, Riak. и т.п.
Иллюстрированная презентация :
Колонно-ориентированные базы данных
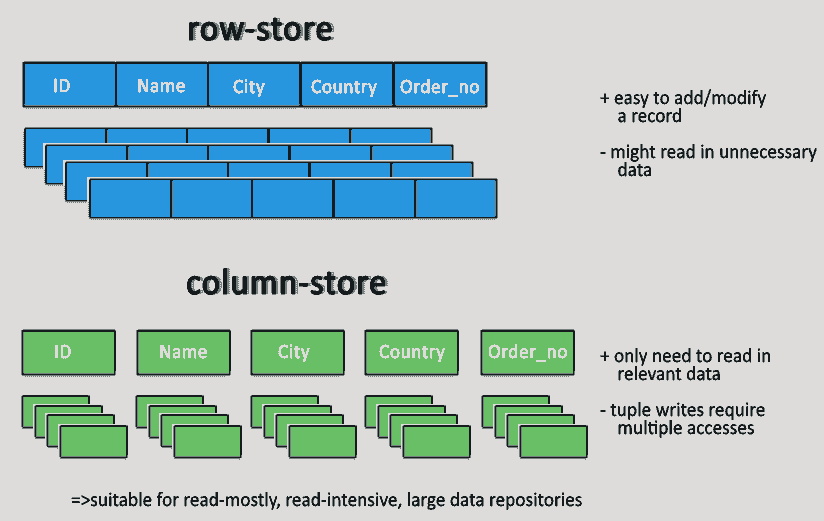
- Базы данных, ориентированные на столбцы, в основном работают на столбцах, и каждый столбец обрабатывается индивидуально.
- Значения одного столбца хранятся непрерывно.
- Колонка хранит данные в файлах, специфичных для колонок.
- В хранилищах столбцов обработчики запросов также работают с столбцами.
- Все данные в каждом файле данных столбца имеют одинаковый тип, что делает его идеальным для сжатия.
- Хранилища столбцов могут повысить производительность запросов, поскольку они могут получить доступ к определенным данным столбцов.
- Высокая производительность при агрегировании запросов (например, COUNT, SUM, AVG, MIN, MAX).
- Работает в хранилищах данных и бизнес-аналитике, управлении взаимоотношениями с клиентами (CRM), каталогах библиотечных карточек и т. Д.
Пример базирующихся на столбцах баз данных: BigTable, Cassandra, SimpleDB и т. Д.
Иллюстрированная презентация :
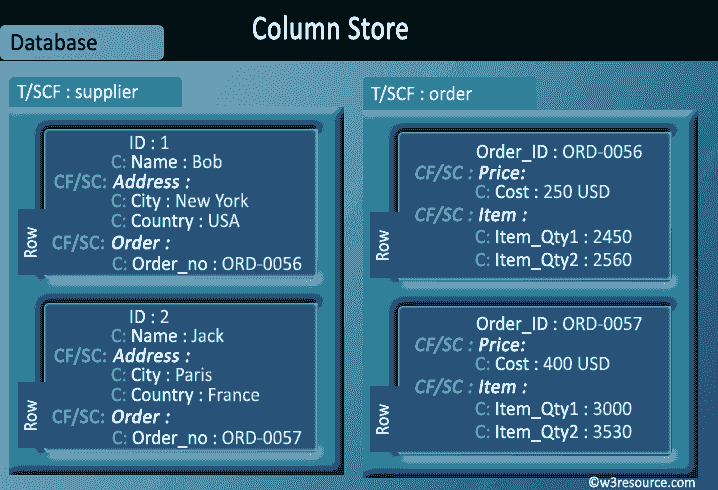
Граф базы данных
Структура данных графа состоит из конечного (и, возможно, изменяемого) набора упорядоченных пар, называемых ребрами или дугами, определенных объектов, называемых узлами или вершинами.
На следующем рисунке представлен помеченный граф из 6 вершин и 7 ребер.
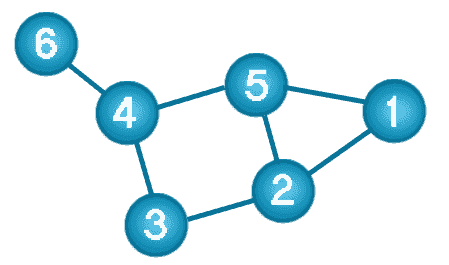
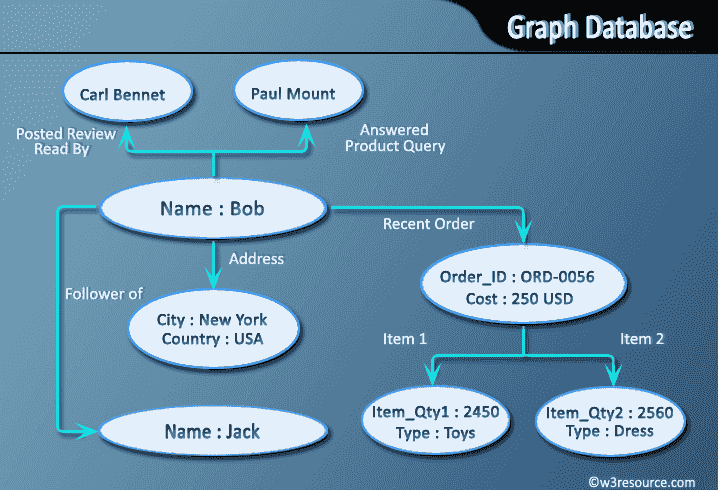
Что такое граф баз данных?
- Графовая база данных хранит данные в графе.
- Он способен элегантно представлять любые данные в доступной форме.
- Графовая база данных представляет собой набор узлов и ребер
- Каждый узел представляет сущность (например, студент или бизнес), а каждое ребро представляет связь или связь между двумя узлами.
- Каждый узел и ребро определяются уникальным идентификатором.
- Каждый узел знает свои смежные узлы.
- По мере увеличения количества узлов стоимость локального шага (или перехода) остается неизменной.
- Индекс для поиска.
Вот сравнение между классической реляционной моделью и моделью графа:
| Реляционная модель | Модель графика |
|---|---|
| таблицы | Набор вершин и ребер |
| Ряды | вершины |
| Колонны | Пары ключ / значение |
| присоединяется | Ребра |
Пример базы данных Graph: OrientDB, Neo4J, Titan.etc.
Иллюстрированная презентация:
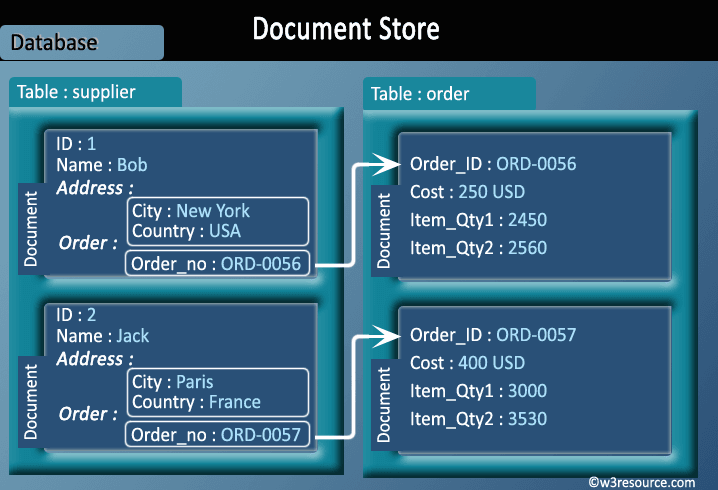
Документно-ориентированные базы данных
- Сборник документов
- Данные в этой модели хранятся внутри документов.
- Документ - это коллекция значений ключа, где ключ позволяет получить доступ к его значению.
- Документы, как правило, не обязательно должны иметь схему, поэтому они гибкие и легко изменяемые.
- Документы хранятся в коллекциях для группировки различных видов данных.
- Документы могут содержать много разных пар ключ-значение, или пары ключ-массив, или даже вложенные документы.
Вот сравнение между классической реляционной моделью и моделью документа:
| Реляционная модель | Модель документа |
|---|---|
| таблицы | Коллекции |
| Ряды | документы |
| Колонны | Пары ключ / значение |
| присоединяется | недоступен |
Пример документов ориентированных баз данных: MongoDB, CouchDB и т. Д.
Иллюстрированная презентация:
Развертывание производства
Существует большое количество компаний, использующих NoSQL. Назвать несколько :
- Mozilla
- саман
- квадрат
- Digg
- Макгроу-Хилл Образование
- Вермонт Общественное Радио
Резюме

Новый контент: Composer: менеджер зависимостей для PHP , R программирования